今天来搭建个wiki知识库,官方网站是:https://www.wikimedia.org/ 著名的维基百科(https://zh.wikipedia.org)就是用的这个程序。 直接进入正题,由于课程文档太费劲,以下内容轻松的一批,由于比较懒,用删库塔来装环境。 下面进入正题,记录步骤: ...
【阿里云】ECS 7天实践训练营-Day02-搭建wiki知识库
【阿里云云开发】笔记(Koa)-Day04
今天了解了一下node的中间件koa (https://koajs.com/) 基本步骤很简单那。。。。。 1.登录云开发平台 2.新建一个产品,如下如所示: 3.等待项目部署完成,进入WEB IDE 4. 把函数改一下就行。。。。如下图。。。。 今天的作业据...

【阿里云】ECS 7天实践训练营-Day01-VuePress搭建
很开心能参加ECS 7天实践训练营,今天是第一天,任务比较简单: 利用云服务器搭建一个简单的云笔记(VuePress)VuePress是以Vue驱动的静态⽹站⽣成器,说白了跟Hexo差不多,生成的都是静态页面。 开始记录: 1.创建云服务器,配置安全组(放行22/80/443/8080) ...
【阿里云云开发】笔记(Web API)-Day03
阿里云云开发(WebAPI)Day03笔记 使用阿里云云开发平台(https://workbench.aliyun.com/)部署midway并与钉钉机器人(webhook)通信 步骤: 登录云开发平台,新建项目选择 点击开发部...
elasticsearch开启简单密码认证
启动 Elasticsearch 程序 ./elasticsearch -d 创建密码 $ ./elasticsearch-setup-passwords interactive Unexpected response code [500] from calling GET http://127.0....
elasticsearch v7.x开放外网访问
rpm方式安装elasticsearch,版本elasticsearch-7.7.0-x86_64.rpm 顺带记录个国内镜像(HW),官方的慢的不要不要的->> 戳我点开 安装完成后,正常启动本地访问正常,想着用外网看一下,结果碰到问题了,根本无法启动elasticsearch进程...
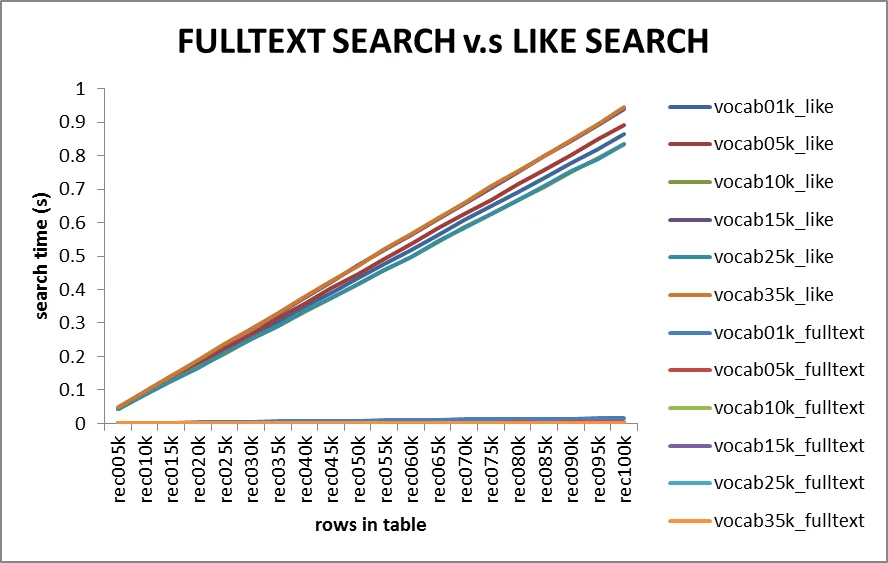
MYSQL全文索引(fulltext)模糊查询抛弃like
对于少量数据来说,使用like和全文索引进行模糊查询耗时看不出来太大差距, 但是一单数据量上去了(10w+条)你就会感觉崩溃了。。。。。 使用like "%key%"简直就是个噩梦,因为用双%会进行全表扫描,啧啧啧想想就恐怖的一批 消耗资源,mysqld占用超高CPU,耗费大量时间,虽然使用...
MYSQL删除重复记录(某个字段)
最近想搞一个网课的题库,用Py抓取了100000+条数据 前期的规则把我写到吐,后边竟然还有重复题目 我丢、、、、放过我好不好。。。。。 这个对于天真的我来说真的是太痛苦了。 于是,找到了下面的语句,可以清理重复行 先查询一下是否有重复记录,然后在进行删除操作吧,...
Python读取文件地址下载
最近手头有个小项目,需要使用到Python抓取内容 就研究了一下Python的写法,读取一个文本文件里的内容(资源网址) 形如: https://cos.tiantiancaige.com/c018e6424d32e00c66514bc525df4b8d_song_1.mp3 https://c...
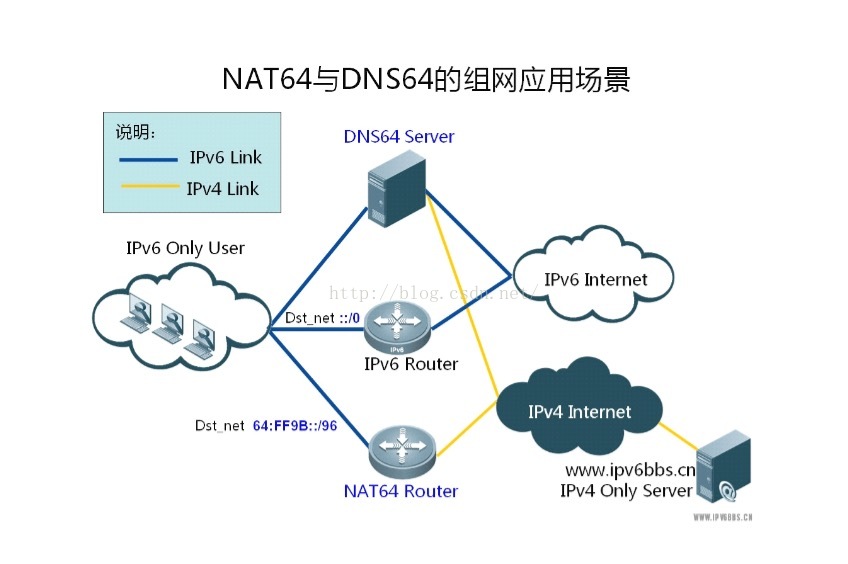
NAT64与DNS64基本原理概述及几个DNS64服务器
1.NAT64与 DNS64背景 在 IPv6网络的发展过程中,面临最大的问题应该是 IPv6与 IPv4的不兼容性,因此无法实现二种不兼容网络之间的互访。为了实现 IPv6与 IPv4的互访,IETF(互联网工程任务组)在早期设计了 NAT-PT的解决方案:RFC2766,NAT-PT通过 IPv6与 IPv4的网络地...
最新评论
@小C:已更新
太棒了感谢。
师哥,原来的翼ZONE已经更换了。以下是...
@情空明月:师哥,原来的翼ZONE已经更...
@GeekX:已添加
师哥,已经添加回链了